20101125-check-object_stream-structure
<< Masa.20101126-update-rpdf2txt | 2010 | Masa.20101124-update-rpdf2txt-debug-import_gkv >>
- Look for the information of 'Object Stream' Structure
- Check Zlib format
- Check encription pdf
- Read how to decrypt in the current version
- Goal
- Check object stream structure / 50%
- Milestones
Web searchSearch Encription RC-4- Read PdfEncrypt class
Confirm a stream in version 1.4 is not zlib byte code too16:00- Trace the encryption process
- Summary
- Commits
- ToDo Tomorrow
- Continue to update rpdf2txt
- Keep in Mind
- Testcases of lib/oddb/html/state/global.rb#grant_download, lib/oddb/html/view/download.rb#to_html
- Debug testcases in test/export/test_server.rb de.oddb.org
- A bug import_gkv Tue Nov 16 02:00:10 2010: de.oddb.org Zubef (PDF)
- Compression (refer to lib/oddb/export/server.rb), Test cases (grant_download, Logging, Reporting)
- Log Error: on production server, de.oddb.org/log/import_dimdi, import_pharmnet
- On Ice
- emerge --sync
Look for the information of 'Object Stream' Structure
Note
- 'First' offset byte looks important
Reference
- PDF Reference version 1.7 (1.5, 1.6) Sec. 3.4.6 http://www.adobe.com/content/dam/Adobe/en/devnet/pdf/pdfs/pdf_reference_1-7.pdf
Experiment
def raw_stream
@raw_stream ||= @src.scan(/stream[\r\n]{1,2}(.*)endstream/mn).to_s
first = @src.scan(/(First\s\d+)/n)
print first, "\toid=", @src.scan(/(\d+) \d+ obj/), "\n"
open("test#{$count}.gz","wb") do |out|
out.write(@raw_stream)
end
Extract raw data of 'Object Stream'
masa@masa ~/ywesee/rpdf2txt $ ruby -I lib bin/rpdf2txt v16.pdf 1 First 7 oid=2545 2 First 688 oid=2546 3 First 15 oid=2547 4 First 52 oid=2548 5 First 7 oid=2549 6 First 24 oid=2550 7 First 1869 oid=2551 8 First 1970 oid=2552 9 First 2105 oid=2553 masa@masa ~/ywesee/rpdf2txt $ ls bin install.rb README test1.gz test3.gz test5.gz test7.gz test9.gz user-stories COPYING lib test test2.gz test4.gz test6.gz test8.gz usage-en.txt v16.pdf
offset.rb
count=0
data=''
File.read("test1.gz").each_byte do |b|
count+=1
if count>7
data << b
end
end
open("out.gz","wb") do |out|
out.write(data)
end
Result
masa@masa ~/work $ ruby offset.rb masa@masa ~/work $ xxd test1.gz 0000000: 789c e332 d033 3030 5040 268b d2b9 3005 x..2.300P@&...0. 0000010: 83dc b99c 4214 0c8d 0cf4 2c2d cd14 cccc ....B.....,-.... 0000020: 4df5 cc4c 2c14 4252 14f4 dd0c 15cc 8df4 M..L,.BR........ 0000030: 0c14 42d2 1480 4491 8286 476a 4e4e be8e ..B...D...GjNN.. 0000040: 4250 6952 a59e a642 4896 826b 0800 0968 BPiR...BH..k...h 0000050: 1643 0a .C. masa@masa ~/work $ xxd out.gz 0000000: 3050 4026 8bd2 b930 0583 dcb9 9c42 140c 0P@&...0.....B.. 0000010: 8d0c f42c 2dcd 14cc cc4d f5cc 4c2c 1442 ...,-....M..L,.B 0000020: 5214 f4dd 0c15 cc8d f40c 1442 d214 8044 R..........B...D 0000030: 9182 8647 6a4e 4ebe 8e42 5069 52a5 9ea6 ...GjNN..BPiR... 0000040: 4248 9682 6b08 0009 6816 430a BH..k...h.C.
Note
- Certainly, 7 bytes is shifted
Test decompression
deflate.rb
require 'zlib' print Zlib::Inflate.new(Zlib::MAX_WBITS + 32).inflate(File.read(ARGV[0]))
Run
masa@masa ~/work $ ruby deflate.rb out.gz
deflate.rb:6:in `inflate': incorrect header check (Zlib::DataError)
from deflate.rb:6
Note
- failed
Consideration
- Actually, this offset bytes 'First' means the offset bytes after the decompression
First: (Required) The byte offset (in the decoded stream) of the first compressed object.
Check Zlib format
References
- Zlib info http://www.futomi.com/lecture/japanese/index.html#zlib (
Good)- zlib data format RFC 1950 ZLIB Compressed Data Format Specification version 3.3
- zlib data format RFC 1950 ZLIB Compressed Data Format Specification version 3.3 (Japanese translation)
- deflate data format RFC 1951 DEFLATE Compressed Data Format Specification version 1.3
- deflate data format RFC 1951 DEFLATE Compressed Data Format Specification version 1.3 (Japanese translation)
- gzip file format RFC 1952 GZIP file format specification version 4.3
- gzip file format RFC 1952 GZIP file format specification version 4.3 (Japanese translation)
- deflate algorithm An Explanation of the Deflate Algorithm
- deflate algorithm An Explanation of the Deflate Algorithm (Japanese translation)
Zlib header (usually) if deflate algorithm is used
- It should be 78 in usual
CMF Byte: 78 CINFO = 7 (32K window size) CM = 8 = (deflate compression)
Check an sample pdf created by pdf-writer
masa@masa ~/work/bak $ xxd hello.gz.pdf .... 00001e0: 6a0a 3c3c 202f 4669 6c74 6572 202f 466c j.<< /Filter /Fl 00001f0: 6174 6544 6563 6f64 650a 2f4c 656e 6774 ateDecode./Lengt 0000200: 6820 3832 203e 3e0a 7374 7265 616d 0a78 h 82 >>.stream.x 0000210: 9ce3 32d0 3330 3050 4026 8bd2 b930 0583 ..2.300P@&...0.. 0000220: dcb9 9c42 140c 8d0c f42c 2dcd 14cc cc4d ...B.....,-....M 0000230: f5cc 4c2c 1442 5214 f4dd 0c15 cc8d f40c ..L,.BR......... 0000240: 1442 d214 8044 9182 8647 6a4e 4ebe 8e42 .B...D...GjNN..B 0000250: 5069 52a5 9ea6 4248 9682 6b08 0009 6816 PiR...BH..k...h. 0000260: 430a 656e 6473 7472 6561 6d0a 656e 646f C.endstream.endo 0000270: 626a 0a0a 3820 3020 6f62 6a0a 3c3c 202f bj..8 0 obj.<< / ...
Notes
- '0a78' after the 'stream' string
- '0a' means linefeed code in linux (UNIX)
- '78' means a part of zlib header, CMF information.
Check the header of Gkv pdf
masa@masa ~/work/bak $ xxd v16.pdf |more 0000010: 3235 3435 2030 206f 626a 0d3c 3c2f 4669 2545 0 obj.<</Fi 0000020: 6c74 6572 2f46 6c61 7465 4465 636f 6465 lter/FlateDecode 0000030: 2f46 6972 7374 2037 2f4c 656e 6774 6820 /First 7/Length 0000040: 3237 322f 4e20 312f 5479 7065 2f4f 626a 272/N 1/Type/Obj 0000050: 5374 6d3e 3e73 7472 6561 6d0d 0a40 a279 Stm>>stream..@.y ...
Notes
- '0d 0a40' after the 'stream'
- '0d 0a' means linefeed code in Windows
- '40' is not the header of zlib, in particular of flate algorithm
- This means, at least, this byte code is NOT of zlib (flate algorithm)
Check encryption pdf
The property of pdf the pdf of version 1.4
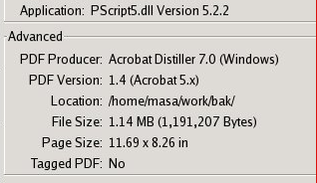
the pdf of version 1.6
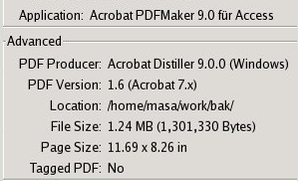
Security (both are same)

Hypothesis
- The 'Object Stream' is encrypted by 128bit RC-4
Check RC-4 encryption
References
- Hannes-san's commit http://scm.ywesee.com/?p=rpdf2txt/.git;a=commit;h=fe20cbe9a8188906558703229d6b547d556075ca
Defer the extraction of decryption data to the point where we are sure to have a valid trailer dictionary. This fixes http://trac.ywesee.com/ticket/185 Note: I'm not sure that Object streams must always be unencrypted. However, in the examples that we have encountered, this has always been the case. Parsing a PDF with encrypted Object streams will most probably fail with the current version.
Notes
- Actually we can see the pdf document on acrobat reader without password,
- It means that probably there is a way to pick up the data from object stream somehow without password
Refence
- Ruby Cipher class http://www.ruby-lang.org/ja/man/html/OpenSSL_Cipher_Cipher.html
I found a class for encrypted object in rpdf2txt lib/rpdf2txt/object.rb#PDFEncrypt class
class PdfEncrypt < PdfObject
class DecryptionError < RuntimeError
end
PADDING = "\x28\xBF\x4E\x5E\x4E\x75\x8A\x41\x64\x00\x4E\x56\xFF\xFA\x01\x08\x2E\x2E\x00\xB6\xD0\x68\x3E\x80\x2F\x0C\xA9\xFE\x64\x53\x69\x7A"
def arc4(key, input)
output = ''
s, j, k = (0..255).to_a, 0, (key*256)[0,256].unpack('C*')
(0..255).each { |x|
j = (j + s[x] + k[x]) % 256
s[x], s[j] = s[j], s[x]
}
i = j = 0
input.each_byte { |b|
i = (i + 1) % 256
j = (j + s[i]) % 256
s[i], s[j] = s[j], s[i]
output << (b ^ s[(s[i] + s[j])%256]).chr
}
output
end
...
Note
- How does the rpdf2txt extract the encrypted object in the current version?
Hypothesis
- In the case of 'Object Stream', the decompression process is called before the decryption process
Check the order of 'decryption' and 'decompression'
Experiment lib/rpdf2txt/object.rb#fdecrypt
def decrypt(pdf_object)
p "getin decrypt"
arc4_key = decrypt_key(pdf_object)
stream = pdf_object.raw_stream
arc4(arc4_key, stream)
end
lib/rpdf2txt/object.rb#flate_decode
def flate_decode(data)
p "getin deflate"
Zlib::Inflate.inflate(data)
end
Test (v14.pdf)
masa@masa ~/ywesee/rpdf2txt $ ruby -I lib bin/rpdf2txt v14.pdf ... "getin decrypt" "getin deflate" Zuzahlungsbefreite Arzneimittel nach � 31 Abs. 3 Satz 4 SGB V Produktstand 01.11.2010 ... "getin decrypt" "getin deflate" Zuzahlungsbefreite Arzneimittel nach � 31 Abs. 3 Satz 4 SGB V Produktstand 01.11.2010 sortiert nach Arzneimittelname ...
Test (v16.pdf)
masa@masa ~/ywesee/rpdf2txt $ ruby -I lib bin/rpdf2txt v16.pdf "getin deflate" 'incorrect header check' when filtering with /FlateDecode
Note
- Probably my prediction looks correct
- In the case of version 1.4, decription is called before the decompression
- but in the case of version 1.6 (Object Stream), the decryption is not called
Next
- I have to understand how the rpdf2txt decrypts the pdf objects
Read how to decrypt in the current version
Confirm a 'stream' object in version 1.4 (not 'Object Stream' but just 'Stream')
masa@masa ~/ywesee/rpdf2txt $ xxd v14.pdf |more 0000250: 2020 2020 0d0a 3139 3130 2030 206f 626a ..1910 0 obj 0000260: 3c3c 2f4c 656e 6774 6820 3131 3633 2f46 <</Length 1163/F 0000270: 696c 7465 722f 466c 6174 6544 6563 6f64 ilter/FlateDecod 0000280: 652f 4920 3637 3935 2f4c 2036 3737 392f e/I 6795/L 6779/ 0000290: 5320 3637 3338 3e3e 7374 7265 616d 0d0a S 6738>>stream.. 00002a0: f0c0 7edb bc44 bc59 ddab 01bb 7dda 810b ..~..D.Y....}...
- 'f0c0' is not the code of zlib header
- so, even in version 1.4, the encryption of rpdf2txt looks working
Trace encryption process (pdf in version 1.4)
1. lib/rpdf2txt/parser.rb#extract_text
def extract_text(callback_handler = SimpleHandler.new)
page_tree.each { |node|
node.text(callback_handler)
callback_handler.send_page
}
callback_handler.send_eof
end
2. lib/rpdf2txt/parser.rb#page_tree
def page_tree
@page_tree ||= build_page_tree()
end
3. lib/rpdf2txt/parser.rb#build_page_tree
def build_page_tree
page_tree_root.build_tree(object_catalogue)
end
4. lib/rpdf2txt/parser.rb#page_tree_root
def page_tree_root
object_catalogue[trailer_dictionary.root_id]
end
5. lib/rpdf2txt/parser.rb#object_catalogue
def object_catalogue
@object_catalogue ||= build_object_catalogue()
end
6. lib/rpdf2txt/parser.rb#build_object_catalogue
def build_object_catalogue
startobj=0
endobj=0
catalogue = {}
@src.scan(/(?:\d+ ){2}obj\b.*?\bendobj\b/mn) do |match|
obj = build_object(match.to_s)
catalogue.store(obj.oid, obj)
end
catalogue.values.select do |obj|
obj.is_a?(ObjStream)
end.each do |obj|
scan_object_stream obj.decoded_stream, catalogue
end
catalogue
end
Notes
- In the case of Gkv pdf in version 1.4, there is no 'ObjStm' object
7. lib/rpdf2txt/parser.rb#trailer_dictionary
def trailer_dictionary
@trailer_dictionary ||= self.build_trailer_dictionary
end
8. lib/rpdf2txt/parser.rb#build_trailer_dictionary
def build_trailer_dictionary
@trailer_dictionary = @object_catalogue.values.find do |obj|
obj.is_a?(TrailerDictionary)
end
startobj = 0
endobj = 0
while(endobj && (startobj = @src.index(/\btrailer/n, endobj)))
if(endobj = @src.index(/startxref/n, startobj))
endobj+= 8
trailer_src = @src[startobj..endobj]
trailer_dictionary = TrailerDictionary.new(trailer_src, @target_encoding)
if(@trailer_dictionary.nil?)
@trailer_dictionary = trailer_dictionary
else
@trailer_dictionary.update(trailer_dictionary)
end
end
end
if @trailer_dictionary.nil? \
&& match = /startxref\s*(\d+)\s*%%EOF/m.match(@src)
startobj = match[1].to_i
endobj = @src.index(/endobj/n, startobj) + 6
xref_src = @src[startobj...endobj]
@trailer_dictionary = TrailerDictionary.new(xref_src, @target_encoding)
end
Note
- What is the TrailerDictionary?
- Reference 3.4 (PDFReference 1.7)
3.4.4File Trailer The trailer of a PDF file enables an application reading the file to quickly find the cross-reference table and certain special objects.
The actual trailer dictionary in Gkv pdf (version 1.4)
trailer^M <</Size 1897/Encrypt 1898 0 R>>^M
- Size: the total number of objects + 1 (this value is 1 greater than the highest object number used in the file.)
- Encrypt: this entry means the document is encrypted. 1898 is encrypt_id in the source code. I do not know '0' and 'R'
Check trailer of v16.pdf
- There is no 'trailer' string in v16.pdf
Experiment
def decode_raw_stream
@decrypted_stream = raw_stream
unless(@decoder.nil?)
print "@decoder="
p @decoder
@decrypted_stream = @decoder.decrypt(self)
end
Test v14.pdf
masa@masa ~/ywesee/rpdf2txt $ ruby -I lib bin/rpdf2txt v14.pdf @decoder=#<Rpdf2txt::PdfEncrypt:0x7fe81ee54648 @file_id="E3EECABE4AA364299244B16AAA72C341", ..."> "getin decrypt" "getin deflate" Zuzahlungsbefreite Arzneimittel nach � 31 Abs. 3 Satz 4 SGB V Produktstand 01.11.2010 ...
Test v16.pdf
masa@masa ~/ywesee/rpdf2txt $ ruby -I lib bin/rpdf2txt v16.pdf "getin deflate" 'incorrect header check' when filtering with /FlateDecode
Note
There is no @decoder object- That is why 'decrypt' method is not called